數(shù)據(jù)科學(xué)的三駕馬車 淺析數(shù)據(jù)分析、機器學(xué)習(xí)與數(shù)據(jù)挖掘的異同
在當(dāng)今大數(shù)據(jù)時代,數(shù)據(jù)處理、數(shù)據(jù)分析、數(shù)據(jù)挖掘和機器學(xué)習(xí)等術(shù)語頻繁出現(xiàn),它們常常被混用,但其核心內(nèi)涵與側(cè)重點各有不同。本文將為您梳理這幾個概念之間的關(guān)系與區(qū)別,特別是探討數(shù)據(jù)分析與機器學(xué)習(xí)是否等同于數(shù)據(jù)挖掘,以及數(shù)據(jù)處理在其中扮演的基礎(chǔ)角色。
核心概念辨析
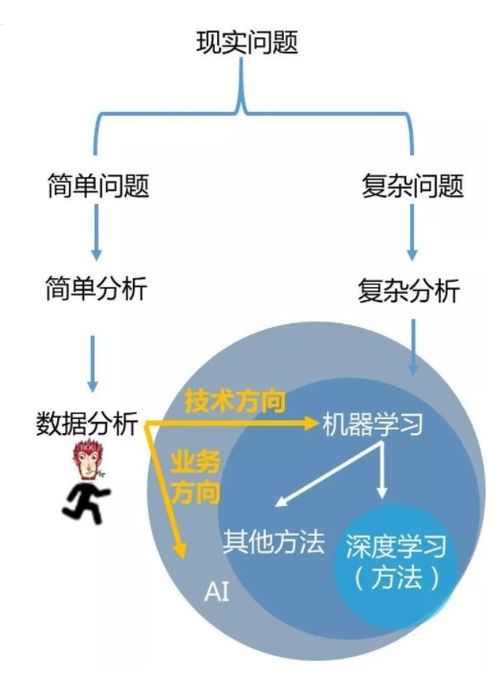
我們可以將這幾個概念視為一個從基礎(chǔ)到高級、從廣泛到具體的連續(xù)光譜。
1. 數(shù)據(jù)處理 (Data Processing)
這是整個流程的基石。數(shù)據(jù)處理指的是對原始數(shù)據(jù)進行收集、清洗、轉(zhuǎn)換、整合和存儲等一系列操作,使其變得規(guī)整、可用。它關(guān)注的是數(shù)據(jù)的“形態(tài)”和“質(zhì)量”,目標是得到一個干凈、結(jié)構(gòu)化的數(shù)據(jù)集,為后續(xù)所有分析工作做好準備。沒有有效的數(shù)據(jù)處理,任何高級分析都如同空中樓閣。
2. 數(shù)據(jù)分析 (Data Analysis)
這是一個更為寬泛的上層概念。數(shù)據(jù)分析旨在通過統(tǒng)計方法、可視化工具和業(yè)務(wù)邏輯,對數(shù)據(jù)進行探索、解釋,以發(fā)現(xiàn)趨勢、模式和洞察,從而回答具體的業(yè)務(wù)問題或支持決策。其核心是“解釋過去”和“理解現(xiàn)狀”。例如,分析上季度的銷售數(shù)據(jù)以找出哪個產(chǎn)品最受歡迎。
3. 數(shù)據(jù)挖掘 (Data Mining)
數(shù)據(jù)挖掘可以看作是數(shù)據(jù)分析的一個特定子集或高級階段。它更側(cè)重于從大型數(shù)據(jù)集中自動或半自動地發(fā)現(xiàn)先前未知的、有效的、潛在有用的模式(如關(guān)聯(lián)規(guī)則、聚類、異常點)。數(shù)據(jù)挖掘更像是“勘探”過程,使用統(tǒng)計、機器學(xué)習(xí)等多種技術(shù),在數(shù)據(jù)中“挖掘”出隱藏的知識。其目標往往是預(yù)測性的或描述性的。
4. 機器學(xué)習(xí) (Machine Learning)
機器學(xué)習(xí)是實現(xiàn)數(shù)據(jù)挖掘(以及更廣泛的數(shù)據(jù)分析)的一種核心技術(shù)手段和工具集。它專注于開發(fā)算法和模型,讓計算機能夠從數(shù)據(jù)中“學(xué)習(xí)”規(guī)律,并利用這些規(guī)律對新數(shù)據(jù)進行預(yù)測或決策。機器學(xué)習(xí)模型(如分類、回歸、聚類算法)是執(zhí)行數(shù)據(jù)挖掘任務(wù)(如客戶分群、銷量預(yù)測)的引擎。
關(guān)系與區(qū)別
現(xiàn)在,我們可以直接回答核心問題:數(shù)據(jù)分析和機器學(xué)習(xí)一樣嗎?它們和數(shù)據(jù)挖掘又是什么關(guān)系?
答案是否定的,它們并不等同,而是相互交織、各有側(cè)重的概念。
- 數(shù)據(jù)分析 vs. 數(shù)據(jù)挖掘:數(shù)據(jù)分析范圍更廣,包含了描述性、診斷性分析;而數(shù)據(jù)挖掘特指通過算法探索數(shù)據(jù)中隱藏模式的過程,更偏向于預(yù)測性和發(fā)現(xiàn)性。可以說,數(shù)據(jù)挖掘是數(shù)據(jù)分析中技術(shù)性更強、更自動化的一個分支。
- 數(shù)據(jù)分析/數(shù)據(jù)挖掘 vs. 機器學(xué)習(xí):這是目的與手段的關(guān)系。數(shù)據(jù)分析和數(shù)據(jù)挖掘是目標領(lǐng)域——我們想通過數(shù)據(jù)達成什么(洞察、預(yù)測、發(fā)現(xiàn)模式)。機器學(xué)習(xí)是實現(xiàn)這些目標的主要技術(shù)方法之一(其他方法還包括傳統(tǒng)統(tǒng)計等)。例如,我們利用“機器學(xué)習(xí)”算法(手段)來“挖掘”客戶流失的預(yù)測模型(數(shù)據(jù)挖掘任務(wù)),最終形成“數(shù)據(jù)分析”報告以指導(dǎo)業(yè)務(wù)行動。
數(shù)據(jù)處理:不可或缺的基礎(chǔ)
在整個鏈條中,數(shù)據(jù)處理是所有這些活動的前置條件和公共基礎(chǔ)。無論是進行簡單的業(yè)務(wù)數(shù)據(jù)分析,還是構(gòu)建復(fù)雜的機器學(xué)習(xí)模型,第一步永遠是獲取和處理好數(shù)據(jù)。高質(zhì)量的數(shù)據(jù)處理能極大提升后續(xù)分析和挖掘的效率和準確性。
與比喻
用一個簡單的比喻來概括:
- 數(shù)據(jù)處理好比是淘金前的篩選和清洗礦石的過程。
- 數(shù)據(jù)分析是研究這些礦石的成分、價值并出具報告的整個工作。
- 數(shù)據(jù)挖掘是報告中特別專注于利用特定工具深入礦脈,尋找未知金礦藏的章節(jié)。
- 機器學(xué)習(xí)則是用來尋找礦藏的最先進的探測儀和自動化挖掘設(shè)備。
因此,它們是緊密相連但又層次分明的概念。在實際的數(shù)據(jù)科學(xué)項目中,這些環(huán)節(jié)往往形成一個閉環(huán)迭代的流程:從數(shù)據(jù)處理開始,經(jīng)過分析與挖掘(運用機器學(xué)習(xí)等方法),產(chǎn)生的洞察又可能指導(dǎo)新一輪的數(shù)據(jù)收集與處理。理解它們的區(qū)別與聯(lián)系,有助于我們更清晰地規(guī)劃項目、選擇工具并有效地從數(shù)據(jù)中創(chuàng)造價值。
如若轉(zhuǎn)載,請注明出處:http://www.leiantech.com/product/79.html
更新時間:2026-02-25 23:45:34